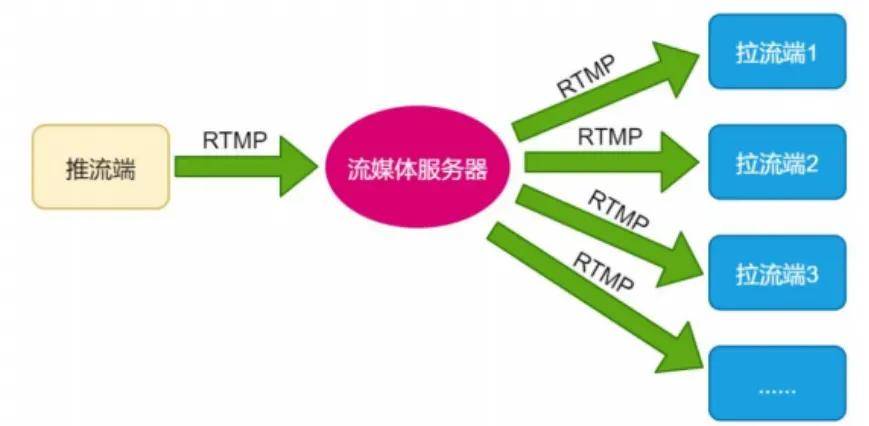
在评估数据缓存效果时,不同类型的自动化工具(实时监控类、性能测试类、深度分析类、云原生专属类)因设计目标和技术特性不同,存在显著的优缺点差异。以下结合工具类型与具体场景,系统对比其核心优劣势,并给出选型参考。
一、实时监控类工具:聚焦 “当前状态感知”
核心工具:Prometheus+Grafana、Redis 原生工具(redis-cli/INFO)、APM 工具(Datadog/New Relic)、netdata
核心目标:实时捕捉缓存运行指标(命中率、内存、延迟),及时预警异常。
优点
实时性强,响应迅速
能秒级更新核心指标(如 Redis 命中率、Memcached 逐出率),支持 “问题发生即发现”。例如:
redis-cli info stats可实时输出keyspace_hits/keyspace_misses,计算命中率仅需 1 秒;
Grafana 看板支持分钟级趋势刷新,缓存雪崩时(命中率骤降)可快速可视化。
可视化友好,低门槛使用
无需复杂配置即可生成直观图表(如命中率折线图、内存饼图),非技术人员也能理解。例如:
Datadog 提供预制的 Redis 监控仪表盘,自动分类 “性能”“资源”“错误” 指标;
netdata 默认启用 Web 界面,无需额外开发即可查看 Memcached 实时连接数。
支持主动告警,防患未然
可基于阈值配置告警(如命中率 <80%、内存使用率> 90%),通过邮件 / 短信 / 企业微信推送。例如:
Prometheus 结合 Alertmanager,缓存穿透时(无效 Key 请求量突增)可触发告警,避免数据库过载。
覆盖多缓存类型,兼容性广
支持 Redis、Memcached、本地缓存(如 Caffeine)等主流缓存,部分工具还能适配云缓存(如 AWS ElastiCache)。
缺点
侧重 “现象监控”,缺乏 “根因分析”
仅能发现 “命中率低”“内存高” 等问题,无法直接定位原因。例如:
监控显示 Redis 内存使用率达 95%,但无法判断是 “大键过多” 还是 “过期策略不合理”,需结合其他工具分析。
历史数据深度有限,长期分析弱
多数工具默认保留短期数据(如 Prometheus 默认保留 15 天),且不支持 “单键级” 历史追溯。例如:
无法查询 “30 天前某热点 Key 的命中次数”,难以评估长期缓存策略效果。
部分工具存在性能开销
APM 工具(如 New Relic)的探针会占用 1%-5% 的服务器 CPU / 内存,高并发场景下可能影响业务;
高频采集(如每秒 1 次)会增加缓存服务器的网络负载(如 Redis 的 INFO 命令需占用带宽)。
对 “非标准指标” 支持不足
无法直接监控 “缓存一致性”(如数据库更新后缓存是否同步失效)、“缓存穿透拦截率” 等自定义指标,需额外开发插件。
二、性能测试类工具:聚焦 “极端场景验证”
核心工具:JMeter、Gatling、Testcontainers、LoadRunner
核心目标:模拟高并发、异常场景(如缓存雪崩 / 穿透),验证缓存的极限能力与容错性。
优点
可模拟真实业务场景,验证缓存有效性
能复现生产级流量(如 10 万 QPS),对比 “开 / 关缓存” 的性能差异,量化缓存价值。例如:
JMeter 通过多线程模拟用户访问,测试 “静态资源缓存” 效果:开缓存时接口响应时间从 500ms 降至 50ms,性能提升 10 倍。
支持故障注入,测试缓存容错性
可主动模拟缓存失效场景,验证系统抗风险能力。例如:
Gatling 脚本中添加 “清除 Redis 缓存” 步骤,测试缓存雪崩时数据库是否扛住流量(如 QPS 从 1 万降至 2000,避免宕机);
Testcontainers 启动真实 Redis 容器,测试 “缓存服务宕机后是否自动切换到本地缓存”。
数据对比性强,优化效果可量化
支持多轮测试对比(如 “LRU 淘汰策略” vs “LFU 淘汰策略”),明确最优方案。例如:
测试显示:LFU 策略下热点 Key 命中率比 LRU 高 12%,可指导生产环境配置调整。
覆盖 “全链路测试”,关联上下游依赖
可联动数据库、API 网关等组件,测试缓存对整个链路的影响。例如:
验证 “缓存 + 数据库” 的一致性:更新数据库后,测试缓存是否被正确清除(避免脏读)。
缺点
模拟场景与生产存在差异,结果有偏差
测试环境的硬件(如 CPU / 内存)、流量模型(如用户分布)与生产不同,可能导致 “测试通过但生产故障”。例如:
JMeter 模拟的 10 万 QPS 是 “均匀请求”,而生产是 “突发流量”,缓存雪崩测试结果可能不准确。
配置复杂,技术门槛高
需要编写脚本(如 JMeter 的 HTTP 请求脚本、Gatling 的 Scala 脚本),且需懂 “并发模型”(如线程组设置、 Ramp-Up 时间),新手需 1-2 周学习。
测试成本高,耗时长
高并发测试(如 100 万 QPS)需搭建多节点测试环境(如 10 台压测机),且单轮测试可能耗时数小时,迭代优化周期长。
无法实时反映生产状态,仅用于测试环境
不能监控生产缓存的动态变化,仅能在发布前验证 “预期效果”,生产中突发问题无法通过此类工具解决。
三、深度分析类工具:聚焦 “根因定位与优化”
核心工具:Redis Memory Analyzer (RMA)、Cachegrind、perf、Redis RDB Analysis
核心目标:挖掘缓存问题的深层原因(如大键、CPU 缓存未命中),优化缓存结构与代码。
优点
支持 “精细化分析”,定位根因精准
能深入到 “单键 / 代码行” 级别,解决实时监控无法覆盖的问题。例如:
RMA 分析 Redis 内存,发现 “前缀为 user:info 的键占 70% 内存”,且多为 10MB 以上的大键,进而优化为 “哈希表拆分”;
Cachegrind 分析 CPU 缓存,发现 “循环中随机访问数组” 导致 D1 缓存未命中率达 40%,调整为 “顺序访问” 后性能提升 30%。
覆盖 “底层性能”,优化深度足
可分析硬件级缓存(如 CPU 的 L1/L2/L3 缓存)、缓存编码方式(如 Redis 的 ziplist/intset)等底层细节。例如:
perf 通过硬件计数器,获取 “LLd(最后一级数据缓存)未命中率”,定位 “频繁创建临时对象导致缓存失效” 的问题。
支持 “长期策略优化”,而非短期应急
可基于历史数据(如 RDB 文件)分析缓存生命周期,优化过期策略、数据结构。例如:
解析 30 天的 RDB 文件,发现 “90% 的键在 24 小时内无访问”,将过期时间从 7 天调整为 1 天,内存使用率下降 40%。
缺点
技术门槛极高,需专业知识
需理解缓存原理(如 Redis 的内存编码、CPU 缓存的局部性原理)、工具语法(如 perf 的事件采集参数-e cache-misses),仅适合资深工程师。
RMA 的 “单键分析” 需懂 Redis 数据结构(如哈希表、有序集合),否则无法解读结果。
分析过程耗时,影响生产风险
解析大 RDB 文件(如 100GB)需数小时,且分析时会占用 Redis 的 CPU / 内存(如执行debug object命令),生产环境需谨慎操作(建议在从节点执行)。
Cachegrind 是 “模拟执行” 工具,分析大型程序(如 100 万行代码)需数小时,效率低。
不支持实时分析,仅离线使用
需先采集数据(如 RDB 文件、perf 日志),再离线分析,无法实时定位生产中突发的缓存问题(如瞬时命中率骤降)。
工具通用性差,多为 “单一场景” 设计
RMA 仅支持 Redis,无法分析 Memcached;
Cachegrind 仅适合 CPU 缓存分析,不支持内存缓存(如 Redis)的键值分析。
四、云原生专属工具:聚焦 “云环境集成”
核心工具:AWS CloudWatch、阿里云 ARMS、Google Cloud Monitoring、Azure Monitor
核心目标:适配云缓存服务(如 AWS ElastiCache、阿里云 Redis),实现 “监控 - 运维 - 优化” 一体化。
优点
无缝集成云服务,零运维成本
无需手动部署监控组件,云厂商已预装探针,自动采集缓存指标。例如:
开通 AWS ElastiCache 后,CloudWatch 自动获取 “CacheHits”“CacheMisses”“CPUUtilization” 等指标,无需配置redis_exporter。
支持 “全栈监控”,关联云资源
可联动云数据库(如 AWS RDS)、云服务器(EC2)、负载均衡(ELB),分析缓存与上下游的依赖关系。例如:
阿里云 ARMS 发现 “Redis 缓存命中率低” 时,自动关联 RDS 的 CPU 使用率(突增 30%),定位 “缓存未生效导致数据库压力大”。
弹性适配云环境,扩展能力强
云缓存实例扩容(如从 2GB 升级到 10GB)后,工具自动同步指标采集范围,无需手动调整配置。例如:
Google Cloud Monitoring 在 ElastiCache 节点增加后,自动新增节点的监控面板,无需重新部署。
提供托管分析服务,降低使用门槛
部分工具内置 AI 分析功能(如阿里云 ARMS 的 “智能诊断”),自动识别 “缓存热点 Key”“内存泄漏” 等问题,无需人工分析。
缺点
厂商锁定严重,迁移成本高
工具与云厂商强绑定,切换云平台时需重新搭建监控体系。例如:
从 AWS 迁移到阿里云后,CloudWatch 的仪表盘、告警规则无法复用,需重新配置 ARMS。
定制化能力弱,不支持特殊场景
仅支持云厂商预设的指标,无法监控 “自定义缓存策略”(如自研本地缓存)。例如:
无法通过 CloudWatch 监控 “基于 Caffeine 的本地缓存命中率”,需额外开发自定义指标插件。
成本高,大规模使用不划算
按 “指标采集频率”“数据存储时长” 收费,高频采集(如每秒 1 次)+ 长期存储(如 1 年)的成本可能超过缓存服务本身。例如:
AWS CloudWatch 每自定义指标每月收费 0.10 美元,100 个指标每年需 1200 美元。
数据安全性依赖云厂商,隐私风险
缓存指标(如键名、访问频率)需上传至云厂商服务器,敏感业务(如金融)可能存在数据泄露风险。
五、各类工具优缺点汇总与选型建议
| 工具类型 | 核心优势 | 核心劣势 | 适用场景 | 推荐工具组合 |
|---|---|---|---|---|
| 实时监控类 | 实时性强、可视化好、支持告警 | 无深度分析、历史数据有限 | 生产环境日常监控、异常预警 | Prometheus+Grafana(开源)、Datadog(商业) |
| 性能测试类 | 模拟极端场景、量化优化效果 | 场景偏差、配置复杂、成本高 | 发布前验证缓存策略、容灾测试 | JMeter(中小并发)、Gatling(高并发) |
| 深度分析类 | 根因定位精准、支持底层优化 | 技术门槛高、耗时、影响生产风险 | 缓存性能瓶颈优化、长期策略调整 | RMA(Redis 内存)、perf(CPU 缓存) |
| 云原生专属类 | 零运维、全栈集成、弹性适配 | 厂商锁定、成本高、定制化弱 | 云环境(AWS / 阿里云)下的缓存监控 | AWS CloudWatch(AWS 用户)、阿里云 ARMS(阿里云用户) |
总结
没有 “万能工具”,实际应用中需组合使用多类工具:
生产监控:用 “实时监控类”(如 Prometheus+Grafana)保障日常稳定,搭配 “云原生工具”(如 ARMS)简化运维;
问题优化:用 “深度分析类”(如 RMA+perf)定位根因,再用 “性能测试类”(如 JMeter)验证优化效果;
成本控制:开源工具(如 Prometheus、JMeter)适合中小团队,商业工具(如 Datadog、ARMS)适合大型企业(追求效率与稳定性)。
审核编辑 黄宇